Raft 算法及实现
1 | Raft is a consensus algorithm for managing a replicated log。 |
Raft是用于管理复制日志的共识(一致性)算法,和multi-Paxos作用一样,但更加易于理解和实现,广泛应用于分布式存储、协调服务。一致性算法是在复制状态机(Replicated State Machine)的背景下提出的,状态机是确定性的,如果多个相同状态机的副本开始于StartStart状态,以相同的次序收到相同的输入会到达相同的状态,并产生相同的输出。分布式环境下,系统的设计为了容错(节点宕机、网络隔离)通常采用某种共识算法,如Paxos、ZAB、Raft,来在维护多节点的一致性,从而保证高可用。
Raft相比于其它共识算法,有如下特征:
- 强leader
- Leader 选举
- 成员变更
Raft算法子问题
- Leader 选举
- 节点有如下三种角色:
- leaeder
- follower
- candidate
- 选举超时时间(election timeout)
- MTBF 平均故障间隔
- broadcastTime 是并行发送RPCs并收到响应的时间Raft 使用随机(150-300ms)的election timeouts,大多数时候同一时刻只会有一个节点发起选举,来防止split votes.
1
broadcastTime << electionTimeout << MTBF
- 节点有如下三种角色:
- Log replication/compaction
- Safety
- Elction Safety
每个任期最多只能选出一个leader - Leader Append-Only
leader 不会覆盖或者删除log entries,只能追加写入 - Log Matching
如果两个日志包含同一个log entry(index和term都一样),那么这两个日志文件log entry及以前的日志多是相同的 - State Machine Safety
如果一个节点已经将一个索引的log entry应用到状态机中,那么其它节点不可以在相同的索引位置应用一个不同的log entry
- Elction Safety
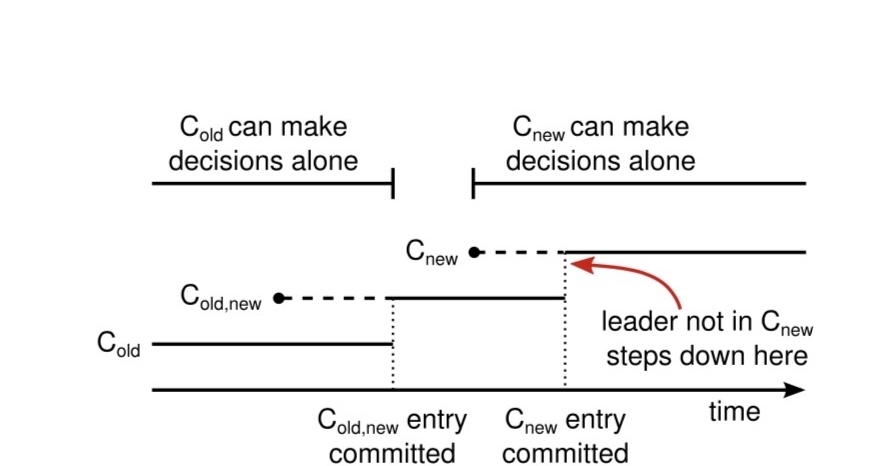
两阶段成员变更
防止两个leader出现,采用joint consensus- 包含old 和 new的配置的log entries
- 旧配置和老配置中的节点都可以作为leader
- 选举和提交日志需要在新/旧配置中的节点上都满足大多数
- C(old,new)配置
- C(new)配置
- isssues
- Observer(not-voting)非投票节点,用于新节点加入集群前只复制,不投票
- 新集群配置不含旧集群leader节点
旧配置节点可能可能成为leader - 被移除的节点(不在新配置中)会破坏集群
收不到心跳,发起RequestVote RPCs,解决办法是在minimum election timeout时间内,不更新term或给其它candidate投票
Raft 存储及RPC
- Raft 中持久化的状态数据
1
2
3
4
5Persistent state{
currentTerm,
votedFor,
log[]
} - Raft 非持久化的数据
1
2
3
4
5
6
7
8Volatile state on all servers{
commitIndex 最大的日志log entry索引
lastApplied 最大的已应用到状态机的log entry索引
}
Volatile state on leaders{
nextIndex[] 下一个即将复制给某个follower的log entry索引
matchIndex[] 已经复制给每一个follower的最大log entry索引
} Raft RPC
RequestVote RPC
请求1
2
3
4
5
6{
term 候选者任期
candidateId 候选者ID
lastLogIndex 候选者的最后一个log entry 索引
lastLogTerm 候选者最后一个log entry 的term
}响应
1
2term current term
voteGranted true means candidate received voteVote Request 接受者是否投票的规则:
- 回复 false if term < currentTerm
- 如果没有给任何选选者投票且候选者log不落后于自己的日志,则true
AppendEntries RPC
请求1
2
3
4
5
6
7
8{
term leader的term
leaderId
prevLogIndex 上一条log entry的日志索引
prevLogTerm 上一条log entry的日志term
entries[] 本次请求的append 的日志
leaderCommit leader的 commitIndex
}响应
1
2current current term,for leader to update itself
success true如果follower包含entry能和(prevLogIndex,prevLogTerm)匹配上AppendEntries接受者实现:
- 回复false 如果 term < currentTerm
- 回复false 如果 log 不包含log entry能和(prevLogIndex,prevLogTerm)匹配上
- 如果任何现有的log entry和新的冲突(同样的index,不同的term),删除它及以后的log entry
- 追加新的log enties到日志
- 如果leaderCommit > commitIndex,更新 commitIndex=min(leaderCommit,index of last new entry)
遵循的规则
- Servers遵循的规则:
- if commitIndex > lastApplied,更新lastApplied并应用日志到状态机
- if RPC 请求或者响应的 term(T)> currentTerm,更新currentTerm =T,变成follower
- Follower遵循的原则:
- 响应来之候选者和领导者的RPC
- 没有收到当前Leader AppendEnties或者给候选人投票并超时,则变成候选人
- Candicate遵循的规则:
- 在和候选人交流和启动选举时
- currentTerm自增
- 投票给自己
- 重置election timer
- 发送 RequestVote RPCs给所有的server
- 获得大多数选票,变为leader
- 收到新Leader的AppendEnties RPC,变成follower
- 如果选举超时,开启新的选举
- 在和候选人交流和启动选举时
- Leader 遵循的原则:
- 一旦成为Leader,发送心跳给所有的server,防止选举超时
- 收到client请求,追加entry 到本地日志,等状态机应用以后再回复client
- 如果 last log 索引 >= nextIndex,发送以nextIndex开始的AppendEntries RPC
- 成功,更新follower对应的 nextIndex和matchIndex
- 由于日志不一致导致失败,则减小nextIndex并重试,找到最近一致log
- 存在一个N > commit index,且大多数的matchIndex[i]>=N并且log[N].term==currentTerm
将commitIndex = N
安全约束
- (lastLogTerm,lastLogIndex) 而元组比较
- up-to-date: 保证包含所有已提交的log entry
- 不能依靠绝大多数策略提交非自己任期内的log entry?
会出现log 覆盖的情况,https://juejin.im/post/5ce7be0fe51d45775c73dc57
异常情况
- Split选举
- Leader 或者 follower crash 问题
- 非自己任期内的log entry是否成功提交,是不确定的
- follower log match并回退log优化
论文中一条一条回退,对于log差距特别大的情况会有问题
AppendEnties RPC的响应包含follower期望的nextIndex,leader 可以根据它优化match速度 - 为什么需要 preVote?
假设没有preVote,网络隔离后的server 会有一个很大的term,网络恢复后,会导致其它节点变为follower开始选举,但它的日志不是最新的,不会成为新Leader。为避免网络分区节点重新加入集群,引起无效的Election.
Q&A
- 优化
- 心跳风暴
- log+ snapshot
- recommand leader
用于防止leader集中到单个节点,导致单节点I/O负载过高
- Kafka 如何做快照?
- checkpoint
Log compaction
- 快照内容
- 状态机数据
- 元数据
- last included index
- last included term
- 最新的集群配置
- 各节点独立做状态机快照
- leader 需要给慢的follower/新加入的节点发快照RPC
InstallSnapshot RPCResult:1
2
3
4
5
6
7
8
9{
term leader's term
leaderId so follower can redirect clients
lastIncludedIndex
lastIncludedTerm
offset 当前的数据在snapshot file 中的偏移量
data[] snapshot 中的chunk 数据
done 是否是最后一个snapshot chunk
}接收快照节点的实现:1
2
3{
term current term
}- 立即回复 如果term < currentTerm
- 当offset=0,创建新的snapshot
- 将chunk 写到snapshot file制定偏移量位置
- 回复并等待data chunk 如果done = false
- 保持snapshot file,丢弃旧的 或 不完成的snapshot 文件
- 如果 已经有 snapshot’s last included entry,只保留后续的chunck 并回复
- 丢弃 整个日志
- 使用snapshot 内容 重置状态机
- 快照内容
Raft 和 multi-Paxos、ZAB的异同?
- Raft是强leader
- 不允许有日志不连续的情况
- Paxos 任意节点可以成为leader,只是需要一个恢复过程
- Paxos 允许乱序提交(日志空洞)
为什么需要两阶段配置变更?什么情况下,会发生双主:
假设现有集群3个节点,添加两个节点,老集群中只有leader收到新的配置,这时发生网络隔离可能出现双主。