Kafka server 入门
Kafka在大数据、流式计算领域得到了广泛的应用,作为一个非常成熟的MQ产品,其中有许多值得学习借鉴的地方,本篇作为梳理Kafka设计和实现的提纲式文章,记录了梳理代码过程中的关键点及一些思考。
特性
- 流式数据存储、发布/订阅消息系统
- Kafka Qos level
- acks=0, 无ack
- acks=1, leader可靠
- acks=-1, ack all
- exactly once
- transaction
Kafka server
- KafkaServer 启动类
- KafkaApis 请求处理的入口
关键的类设计
- ReplicaManager
- Partition
1
2
3{
allReplicasMap,// follower复制状态
} - Log/LogSegment
OffsetIndex:
1
(largestOffset,physicalPosition)
- Replica
1
2
3
4{
hightWatermarkMetadata(HW),
logEndOffsetMetadata(LEO)
} - KafkaController
- ControllerContext
1
2
3
4
5
6
7
8
9
10{
shuttingDownBrokerIds,
epoch, // contoller epoch
allTopics, // all topics
partitionReplicaAssignmentUnderlying, // topic->partition->replicaspartition分配的replica元数据
partitionLeadershipInfo,// leaderIsrAndControllerEpoch
partitionsBeingReassigned, // reassigning partition
liveBrokersUnderlying, // live Brokers
liveBrokerIdAndEpochsUnderlying, //live broker,epoch
} - Broker
- PartitionState
1
2
3
4
5
6
7
8
9{
controllerEpoch,
leader,
leaderEpoch,
isr,
zkVersion,
replicas,
*isNew*
} - TopicMetadata
- PartitionMetadata
1
2
3
4
5
6
7
8{
partition,
leader,
leaderEpoch,
replicas,
isr,
offlineReplicas
} - ReplicaStateMachine
- electLeaderForPartitions:partition leader election
- PartitionLeaderElectionAlgorithms
- uncleanLeaderElectionEnabled
- live && isr
Kafka produce
- 关键配置:
- client.id
- ReplicaManager 生产消息的流程
- appendToLocalLog
- if acks=-1, deley producer的 watcher 队列,所有replica等待复制完成
完成的标准:- highWatermark(HW,已提交)>= 本次生产的最大offset+1
- isr列表副本数量>=minIsr
- HW(highwatermark)和LEO(log end offset)何时更新?
Kafka consume
- 关键配置:
- group.id
- client.id
Consumer FetchRequest(Client consumer)
- 查找协调者(ConsumerCoordinator.lookupCoordinator) FIND_COORDINATOR
基于groupId hash选择Group metadata topic(consumer_offsets)一个partition所在broker作为协调者 向协调者获取元数据和发起组消费协调
- topic 元数据更新,ConsumerCoordinator.poll()
MetadataUpdater 更新相关topics的METADATA,handleCompletedMetadataResponse - 消费组协调(ensureActiveGroup)(JOIN_GROUP|SYNC_GROUP)
- 向协调者coordinator(Kafka Coordinator),发送 JoinGroupRequest
- GroupCoordinator.doJoinGroup|onCompleteJoin
- GroupState:Empty|PreparingRebalance|PreparingRebalance
- DelayedJoin
- onJoinLeader/onJoinFollower
ConsumerGroup 的leader 会拿到所有member metadata,并根据分配策略给consumer分配partition;
- topic 元数据更新,ConsumerCoordinator.poll()
Fetch message
- FetchIsolation
- LogReadResult
- segment.read
- LogOffsetMetadata
- GatheringByteChannel
- FileRecords.writeTo
- FetchDataInfo
- DelayedFetch
- KafkaChannel
- TransportLayer
待续….
Rebalance
哪几种情况,会导致消费组进入rebalance状态?- 当前处于Stable状态,有新的member JOIN_GROUP,LEAVE_GROUP
- prepareRebalance 合法的previous状态{Stable, CompletingRebalance, Empty}
- 方法GroupCoordinator.prepareRebalance
- delay groupInitialRebalanceDelayMs 等待其它member 直到join超时
- GroupCoordinator.onCompleteJoin
- SYNC_GROUP
- 存储分配结果 consumer_offsets
- 响应consumer SYNC_GROUP
- Stable
Group State
- PreparingRebalance
- CompletingRebalance:Group is awaiting state assignment from the leader
- Stable,状态新的consumer 加入导致元数据变更,所有member rejoin
- Dead
- Empty
- 参数
- rebalance_timeout
- group.initial.rebalance.delay.ms
- 查找协调者(ConsumerCoordinator.lookupCoordinator) FIND_COORDINATOR
- Follower FetchRequest(REPLICA_ID >=0,表示请求来自follower)
- updateFollowerLogReadResults
- lastCaughtUpTimeMs 计算?
- maybeExpandIsr, 更新isr(zk,cache),再计算HW
- 什么情况下会加入/移除isr?
- 加入 replica LEO>=leader HW,更新HW
- 移除 宕机、周期性清理isr(lagTime> replicaMaxLagTimeMs)
- HW怎么更新?
在isr里面或者满足lagTime(now()当对于上一次caughtUpTimeMs的差值)<=replicaLagTimeMaxMs的所有replica的LEO最小值
- 什么情况下会加入/移除isr?
- tryCompleteDelayedRequest
- updateFollowerLogReadResults
Kafka Log/Index存储设计
- Kafka的存储分为日志、索引两类文件,
- 尾部追加Log records
- index
- OffsetIndex
- TimeIndex
- TransactionIndex
- IO方式:
- Log fileChannel
- Index mmap
- check point(检查点)
- LogSegment.recover恢复
- 影响持久化的配置:
- segment.ms,default=600000ms,10min,force
- 影响可靠性的配置:
- acks
- min.insync.replicas(minIsr)
- replication.factor
- replica.lag.time.max.ms(replicaLagTimeMaxMs)
- unclean.leader.election.enable
- Zero copy 设计
Kafka Metadata设计
- zookeeper元数据目录如下:
- cluster
- controller_epoch
- controller
- brokers
- ids
- topics
- topicA
- partitions
- 0
- state
- …
- 5
- 0
- partitions
- topicB
- topicA
- admin
- isr_change_notification
- consumers
- log_dir_event_notification
- latest_producer_id_block
- config
Kafka Controller(broker leader)处理元数据变更事件
- BrokerChange
- 对于新broker:恢复分配给它的partition,并触发partition leader election(OfflinePartitionLeaderElectionStrategy)
- 默认选取liveReplica的第一个replica;
- UpdateMetadataRequest(UPDATE_METADATA) to live brokers
- LeaderAndIsrRequest(LEADER_AND_ISR)
- 对于新broker:恢复分配给它的partition,并触发partition leader election(OfflinePartitionLeaderElectionStrategy)
- BrokerChange
Group Metadata(内置主题consumer_offsets,acks=-1)
- Header.Apiversion=0存储在ZK上;以后存储在coordinator上
- FetchOffsets: GroupCoordinator
- PartitionData
- GroupMetadata:
1
2
3
4
5
6
7
8
9
10
11{
GroupState:{PreparingRebalance|CompletingRebalance|Stable|Dead|Empty}
leaderId: 消费者中的leader,
members: consumer group members,
awaiting join memebers nums:0,
offsets:消费位置,
pendingOffsetCommits:未完成的提交的offsets
pendingTransactionalOffsetCommits:事务未完成的提交的offsets ,
new membr added:标志是否有新consumer 加入
}Kafka选举
Kafka Controller 选举
利用Zookeeper的选举功能进行选举?使用了如下的path:
- /controller(EPHEMERAL)
- /controller_epoch(PERSISTENT)
- /controller注册watcher,/controller被删除时参与Controller选举
- 如果/controller不存在,KafkaController.elect方法
Kafka partition 选举
replica宕机或者新增如何选举?
- 监听brokers
- 获取liveBrokersIds,deadBrokerIds
- deadBrokerIds 上所有的partitions
- 对这部分partitions重新选举,选举规则如下
- 对于单个partition,如果它的ISR至少还有一个Replica存活,选举其中一个作为新的leader;否则2
- 如果允许(unclean.leader.election.enable=true),从存活的Replica中任选择一个作为Leader;否则leader=-1
Kafka 消费协调
Kafka client对PartitionAssignor有三个不同的实现,RangeAssignor和RoundRobinAssignor 都是无状态的;而StickyAssignor会参考上次的分配结果
RangeAssignor(per-topic basis)
- 优先分配单个topic
- 排前面的consumer会分到更多的partition
分配思路:
- 给所有可用的partitions排序
- 给所有的consumers排序
- 计算每个consumer 平均分配partition数(p)
遍历consumers,一次顺序取出p个partitions分配给当前consumer,循环直到分配完成
例如,有如下的协调元数据- 有2个consumers{C0,C1};
- 有2个topics{t0,t1};
- t0有3个partitions{t0p0,t0p1,t0p2};t1有3个partitions{t1p0,t1p1,t1p2}
则partitions 排序的结果是{t0p0,t0p1,t0p2,t1p0,t1p1,t1p2}
分配结果是:
- C0:[t0p0, t0p1, t1p0, t1p1]
- C1:[t0p2, t1p2]
RoundRobinAssignor
- 考虑了consumer 订阅了不同的topics 的情况
分配思路:
- 给所有可用的partitions排序
- 遍历partitions,对于当前partition,去遍历consumers,如果当前consumer订阅了当前partition,怎分配给当前consumer,否则继续遍历consumer
- 假设所有consumers订阅相同topics,仍使用上面的元数据,分配结果如下:
- C0: [t0p0, t0p2, t1p1]
- C1: [t0p1, t1p0, t1p2]
假设consumers订阅不相同topics
有如下的元数据:- consumers{C0,C1,C2}
- topics{t0,t1,t2}
- t0{p0};t1{p0,p1};t2{p0,p1,p2}
- 排序后的partitions{t0p0,t1p0,t1p1,t2p0,t2p1,t2p2}
分配结果:
- C0:[t0p0]
- C1:[t1p0]
- C2:[t1p1, t2p0, t2p1, t2p2]
StickyAssignor
- 原则
- 尽量均匀
- 尽可能保存原有的分配
- 冲突时优先保证均匀
- 同样分订阅相同和不同两种情况讨论
- 订阅相同
实现太复杂- 原则
Kafka network
- SocketServer
- Acceptor
- Processor
高级特性
Exactly once
事务(TransactionManager,read-process-write):transaction_state
https://www.confluent.io/blog/transactions-apache-kafka- lookupCoordinator
- initTransaction
- INIT_PRODUCER_ID
- beginTransaction
- TransactionCoordinator
- WriteTxnMarkersRequest
- EndTransactionMarker
Kafka 限流机制
- Throttle
Q&A 思考
- Kafka如何做到高可用?(不丢数据)
涉及如下几个子问题- 不同的acks级别是如何保证的?
- partition replicas怎么做选举?
- 元数据服务设计是如何去中心化的?
- 相比与其它MQ有什么优缺点?
- 适用于高吞吐,对可靠性要求不高(少量丢失数据业务可以忍受)的场景(日志、大数据抽取等)
- 对电商类低延迟交易,金融级完全可靠存储的场景,没有保障
- 单broker Partition 过多会导致性能下降(划分太细)
- 产品级监控、消息轨迹、易用性方面不够
- Kafka 单副本刷盘机制?
- Kafka会丢消息吗?
某些场景下会丢消息?- LogSegment.open/Log flush
Kafka是CA or AP系统?
CA,but P通常都是需要的Kafka 幂等和事务?
- 发送幂等(pid+sequence number)
- 消费幂等?
- Kafka rebalance?
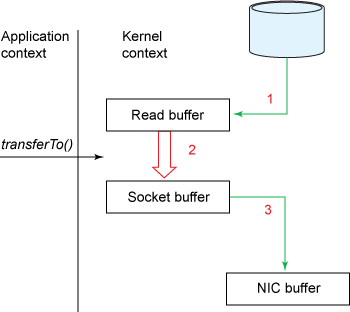
- Kafka zero-copy?数据直接从内核缓冲区直接送入Socket缓冲区
- mmap
- FileChannel.transferTo
- GatheringByteChannel
- Kafka isr 和Raft 多副本的异同?